大家好,我是小寒。
今天给大家介绍一个强大的算法模型,CLIP
CLIP (Contrastive Language–Image Pre-training) 是一个由 OpenAI 开发的多模态预训练模型,它能够理解图像和相关文本之间的关系。CLIP 的核心思想是通过对比学习(Contrastive Learning)训练一个模型,使其能够将图像和描述性文本映射到同一个向量空间中。
多模态深度学习专注于开发能够处理和理解多种类型数据(如文本、图像和音频)的算法和模型,而不像传统模型只能处理单一类型的数据。
CLIP 模型的主要意义在于其跨模态学习能力,即能同时处理和理解图像及其文本描述。这种能力使得 CLIP 在处理视觉任务时不仅局限于固定的数据集和预定义的类别,而是能够理解在训练时未曾见过的概念或对象。此外,CLIP 可以使用自然语言描述来进行零样本学习(zero-shot learning),即直接使用文本描述来进行图像识别,而不需要额外的模型训练。
零样本学习(zero-shot learning)是指模型尝试预测在训练数据中未出现过一次的类别。
例如,经过对狗和猫进行分类训练的图像分类器有望在我们赋予它的任务上表现出色,即对狗和猫进行分类。我们通常不会期望经过对狗和猫进行训练的机器学习模型能够很好地检测浣熊。而 CLIP 往往在它们没有直接接受过训练的任务上表现良好,这被称为 “零样本学习”。
CLIP 架构
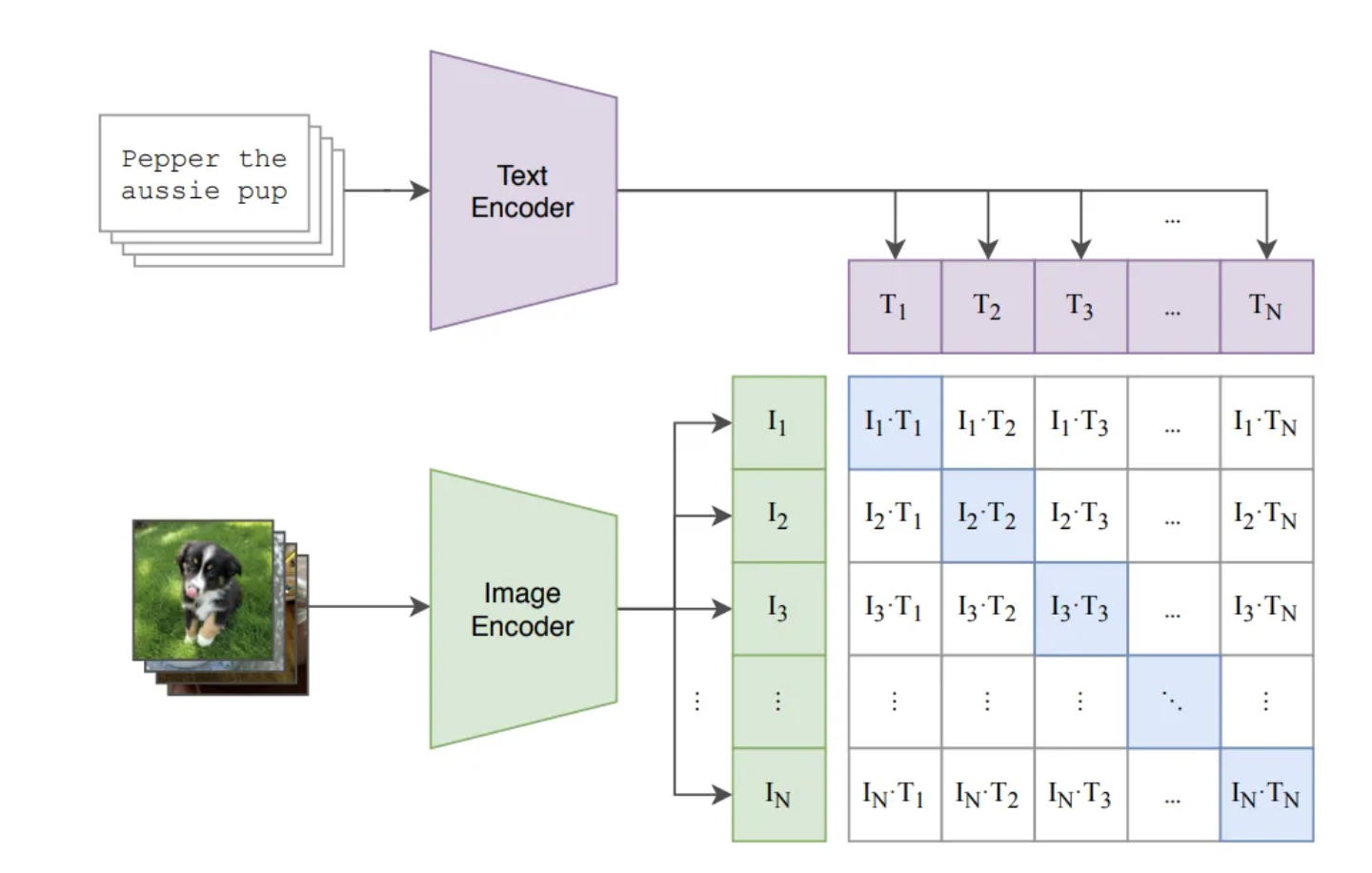
CLIP 模型包括两个主要的组成部分:一个图像编码器和一个文本编码器,这两者共同工作来将图像和文本映射到一个共同的特征空间中。
- 图像编码器
通常使用卷积神经网络(CNN)或 Vision Transformer(ViT)架构。这些编码器被训练来处理图像数据,提取重要的视觉特征。
- 文本编码器
通常基于 Transformer 架构,设计用于处理文本数据。这些编码器被训练来处理文本数据,提取重要的文本特征。
两个编码器都输出嵌入向量(即高维特征表示),这些向量随后通过对比损失函数进行优化,确保图像与其相应的文本描述在特征空间中彼此接近,而与不相关文本的距离则较远。通过这种方式,CLIP 学习如何将图像和文本对齐到同一特征空间,实现跨模态的理解和处理。
假设给定一批 N 个图像和相应的文本描述,会生成 N*N 个图像和文本对,在这些对中,N 对应该具有较高的余弦相似度,而其余 N²-N 个不正确的配对应该具有较低的余弦相似度。
首先,我们通过图像编码器(ViT 或 ResNet 模型)以获取尺寸为 NxI 的图像嵌入。将文本通过文本编码器以获取尺寸为 NxT 的文本嵌入。
为了测量它们在表示上的相似性,我们希望对图像的嵌入和相应的文本的嵌入进行点积。但这两个向量分别是 I 维和 T 维。为了使它们达到相同的维度,我们引入了两个投影(线性)层,一个用于图像,一个用于文本,使它们达到相同的维度 D。经过投影层后,我们将得到两个形状为 NxD 的矩阵。
接下来,将两个矩阵相乘,从而得到一个 BxB 矩阵,其中行表示图像,列表示文本,其值代表了图像(embedding)与文本(embedding)的相似性。
CLIP 损失函数
对于像我这样还没有尝试过对比损失的人来说,这是最有趣的部分。
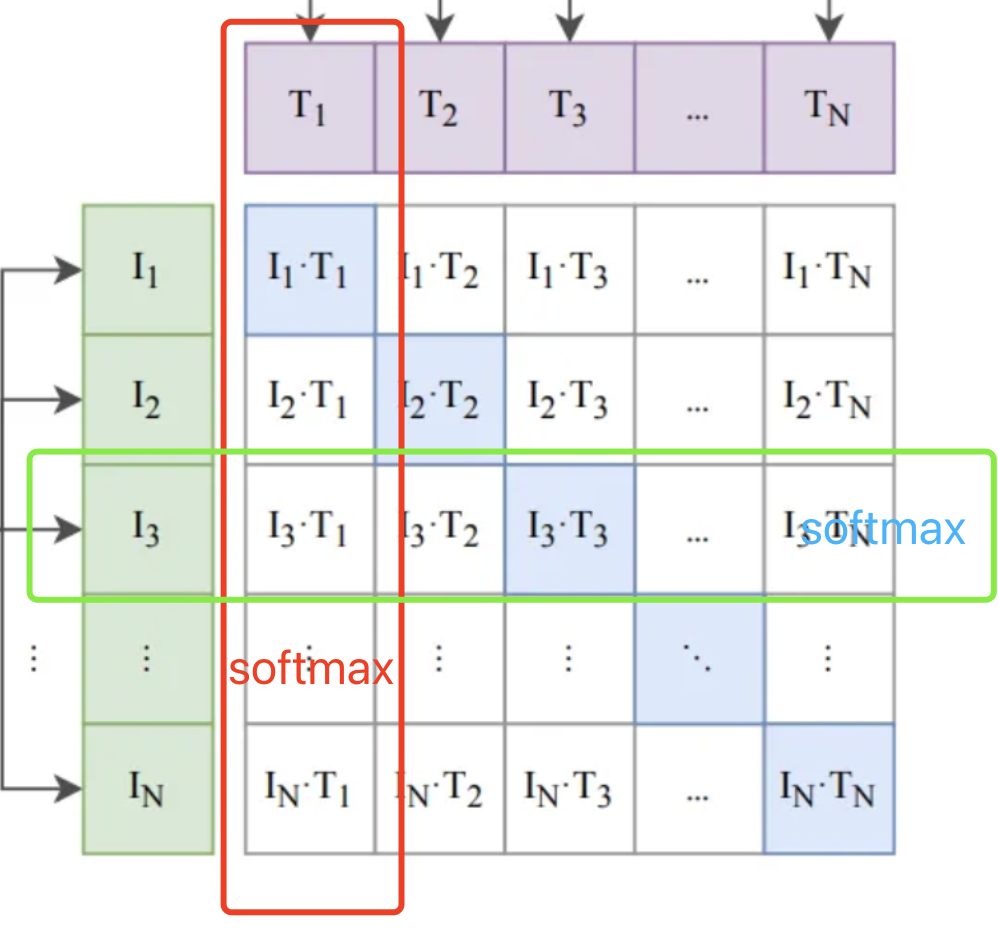
我们知道,我们希望相应图像和文本的向量对齐。这意味着点积必须尽可能接近(矩阵中的对角线元素) 1。对于其他所有内容,我们需要将其推向 0。
因此,对于给定的标题,我们对所有图像的点积取 softmax,然后取交叉熵损失。
同样,对于给定的图像,我们对所有标题重复该过程。
接下来,我们对这两个损失取平均值。然后我们通过反向传播来更新权重。这就是 CLIP 的构建和训练方式。
def contrastive_loss(logits, dim):
neg_ce = torch.diag(F.log_softmax(logits, dim=dim))
return -neg_ce.mean()
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity, dim=0)
image_loss = contrastive_loss(similarity, dim=1)
return (caption_loss + image_loss) / 2.0
def metrics(similarity: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
y = torch.arange(len(similarity)).to(similarity.device)
img2cap_match_idx = similarity.argmax(dim=1)
cap2img_match_idx = similarity.argmax(dim=0)
img_acc = (img2cap_match_idx == y).float().mean()
cap_acc = (cap2img_match_idx == y).float().mean()
return img_acc, cap_acc
应用实例
由于 CLIP 模型具有理解图像与文本的能力,使其在多种应用场景中表现出色。
以下是一些主要的应用例子。
- 零样本图像分类
在没有训练特定类别的情况下识别图像中的对象。
- 图像搜索
CLIP 可以用来实现基于文本的图像检索。
- 多模态内容生成
CLIP 可以与图像生成模型(如DALL·E)结合,根据文本描述生成具体的图像。
下面,我们来看一下 clip 如何进行零样本图像分类。
首先,我们将所有单词插入上下文(提示)并将其传递给文本编码器。接下来,使用余弦相似度公式(简单点积)将所有相应的嵌入与图像嵌入进行比较。最后,我们选择点积最大的文本。

代码实现
关于常量,需要注意的重要一点是嵌入维度。
我们将把 resnet 和 transformers 的输出投影 到 512 维空间中。
EMBED_DIM = 512
TRANSFORMER_EMBED_DIM = 768
MAX_LEN = 128 # Maximum length of text
TEXT_MODEL = "distilbert-base-multilingual-cased"
EPOCHS = 5
BATCH_SIZE = 64
数据
我们下载了 coco 数据集,其中每张图片包含 5 个说明,大约有 82k 张图片。我们取其中的 20% 作为验证集。
考虑到图像主干是使用 imagenet 训练的,我们使用 imagenet 统计数据对其进行标准化,如变换标准化步骤中所示。我们还将图像大小调整为 128x128,以确保它在合理的时间内进行训练。
img = inv_tfm(img)
plt.imshow(np.rot90(img.transpose(0, 2), 3))
plt.title(target)
plt.show()
train_len = int(0.8*len(cap))
train_data, valid_data = random_split(cap, [train_len, len(cap) - train_len])
train_dl = DataLoader(train_data, BATCH_SIZE, pin_memory=True, shuffle=True, num_workers=4, drop_last=True)
valid_dl = DataLoader(valid_data, BATCH_SIZE, pin_memory=True, shuffle=False, num_workers=4, drop_last=False)
模型
主要有两种模型,分别以 resnet34 和 distilbert 作为主干。为了使其支持多种语言,我们只需选择模型 distilbert-multilingual 即可。
Projection 模块从视觉和文本编码器中获取嵌入并将其投影到 512 维空间中。
需要注意两点:
- 我们已经冻结了文本和视觉编码器主干,并且根本不重新训练它们的权重。
- 对于两个编码器,最终输出都被标准化为单位长度。
class Projection(nn.Module):
def __init__(self, d_in: int, d_out: int, p: float=0.5) -> None:
super().__init__()
self.linear1 = nn.Linear(d_in, d_out, bias=False)
self.linear2 = nn.Linear(d_out, d_out, bias=False)
self.layer_norm = nn.LayerNorm(d_out)
self.drop = nn.Dropout(p)
def forward(self, x: torch.Tensor) -> torch.Tensor:
embed1 = self.linear1(x)
embed2 = self.drop(self.linear2(F.gelu(embed1)))
embeds = self.layer_norm(embed1 + embed2)
return embeds
class VisionEncoder(nn.Module):
def __init__(self, d_out: int) -> None:
super().__init__()
base = models.resnet34(pretrained=True)
d_in = base.fc.in_features
base.fc = nn.Identity()
self.base = base
self.projection = Projection(d_in, d_out)
for p in self.base.parameters():
p.requires_grad = False
def forward(self, x):
projected_vec = self.projection(self.base(x))
projection_len = torch.norm(projected_vec, dim=-1, keepdim=True)
return projected_vec / projection_len
class TextEncoder(nn.Module):
def __init__(self, d_out: int) -> None:
super().__init__()
self.base = AutoModel.from_pretrained(TEXT_MODEL)
self.projection = Projection(TRANSFORMER_EMBED_DIM, d_out)
for p in self.base.parameters():
p.requires_grad = False
def forward(self, x):
out = self.base(**x)[0]
out = out[:, 0, :] # get CLS token output
projected_vec = self.projection(out)
projection_len = torch.norm(projected_vec, dim=-1, keepdim=True)
return projected_vec / projection_len
class Tokenizer:
def __init__(self, tokenizer: BertTokenizer) -> None:
self.tokenizer = tokenizer
def __call__(self, x: str) -> AutoTokenizer:
return self.tokenizer(
x, max_length=MAX_LEN, truncation=True, padding=True, return_tensors="pt"
)
损失
def contrastive_loss(logits, dim):
neg_ce = torch.diag(F.log_softmax(logits, dim=dim))
return -neg_ce.mean()
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity, dim=0)
image_loss = contrastive_loss(similarity, dim=1)
return (caption_loss + image_loss) / 2.0
def metrics(similarity: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
y = torch.arange(len(similarity)).to(similarity.device)
img2cap_match_idx = similarity.argmax(dim=1)
cap2img_match_idx = similarity.argmax(dim=0)
img_acc = (img2cap_match_idx == y).float().mean()
cap_acc = (cap2img_match_idx == y).float().mean()
return img_acc, cap_acc
模型
class Model(pl.LightningModule):
def __init__(self,
lr: float = 1e-3
) -> None:
super().__init__()
self.vision_encoder = VisionEncoder(EMBED_DIM)
self.caption_encoder = TextEncoder(EMBED_DIM)
self.tokenizer = Tokenizer(AutoTokenizer.from_pretrained(TEXT_MODEL))
self.lr = lr
def common_step(self, batch: Tuple[torch.Tensor, List[str]]) -> torch.Tensor:
images, text = batch
device = images.device
text_dev = {k: v.to(device) for k, v in self.tokenizer(text).items()}
image_embed = self.vision_encoder(images)
caption_embed = self.caption_encoder(text_dev)
similarity = caption_embed @ image_embed.T
loss = clip_loss(similarity)
img_acc, cap_acc = metrics(similarity)
return loss, img_acc, cap_acc
def training_step(
self, batch: Tuple[torch.Tensor, List[str]], *args: list
) -> torch.Tensor:
loss, img_acc, cap_acc = self.common_step(batch)
self.log("training_loss", loss, on_step=True)
self.log("training_img_acc", img_acc, on_step=True, prog_bar=True)
self.log("training_cap_acc", cap_acc, on_step=True, prog_bar=True)
return loss
def validation_step(
self, batch: Tuple[torch.Tensor, List[str]], *args: list
) -> torch.Tensor:
loss, img_acc, cap_acc = self.common_step(batch)
self.log("validation_loss", loss, on_step=True)
self.log("validation_img_acc", img_acc, on_step=True, prog_bar=True)
self.log("validation_cap_acc", cap_acc, on_step=True, prog_bar=True)
return loss
def configure_optimizers(self) -> torch.optim.Optimizer:
vision_params = {"params": self.vision_encoder.projection.parameters(), "lr": self.lr}
caption_params = {"params": self.caption_encoder.projection.parameters() , "lr": self.lr}
return torch.optim.Adam([vision_params, caption_params])
训练
model = Model(1e-3)
trainer = pl.Trainer(
max_epochs= EPOCHS,
gpus=torch.cuda.device_count(),
gradient_clip_val=1.0,
precision=16
)
trainer.fit(model, train_dl, valid_dl)