什么是 Stacking 算法
Stacking(堆叠)是一种集成学习技术,它结合了多个不同的机器学习模型,以提高整体预测的准确性。这种方法通常用于回归和分类问题。

基本概念
- 基学习器(Base Learners):这些是堆叠过程中的初级学习模型。它们可以是任何类型的学习算法(例如决策树、神经网络、支持向量机等)。
- 元学习器(Meta Learner):也称为第二层学习器,用于学习如何最佳地结合基学习器的预测。
工作流程
- 训练基学习器:首先,基学习器在完整的训练数据集上进行训练。
- 预测及创建新的特征集:每个基学习器在训练集上做出预测,并将这些预测用作新特征,这些新特征用于训练元学习器。
- 训练元学习器:元学习器在这些新创建的特征集上进行训练,学习如何有效地结合基学习器的预测。
Stacking 算法可以在多个层次上进行,即可以使用多个元模型来组合基本模型的预测结果。单层 Stacking 和双层Stacking的示意图如下。
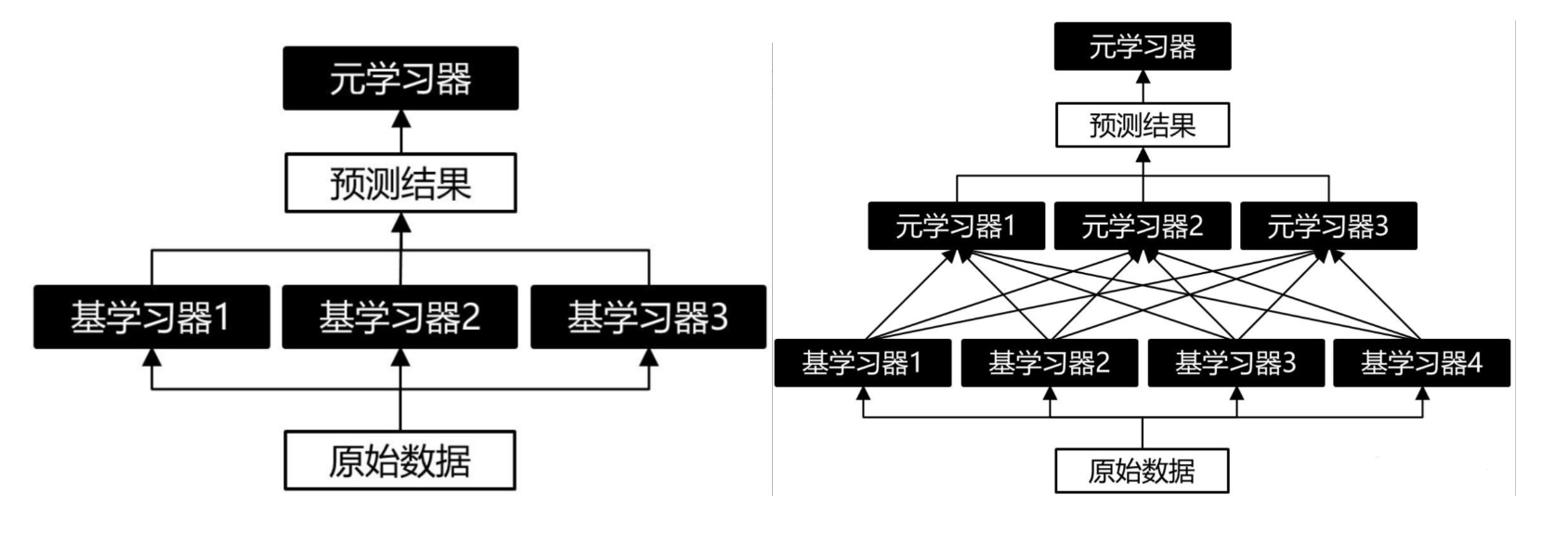
为了防止过拟合,Stacking 算法都会利用K折交叉验证来训练基模型。
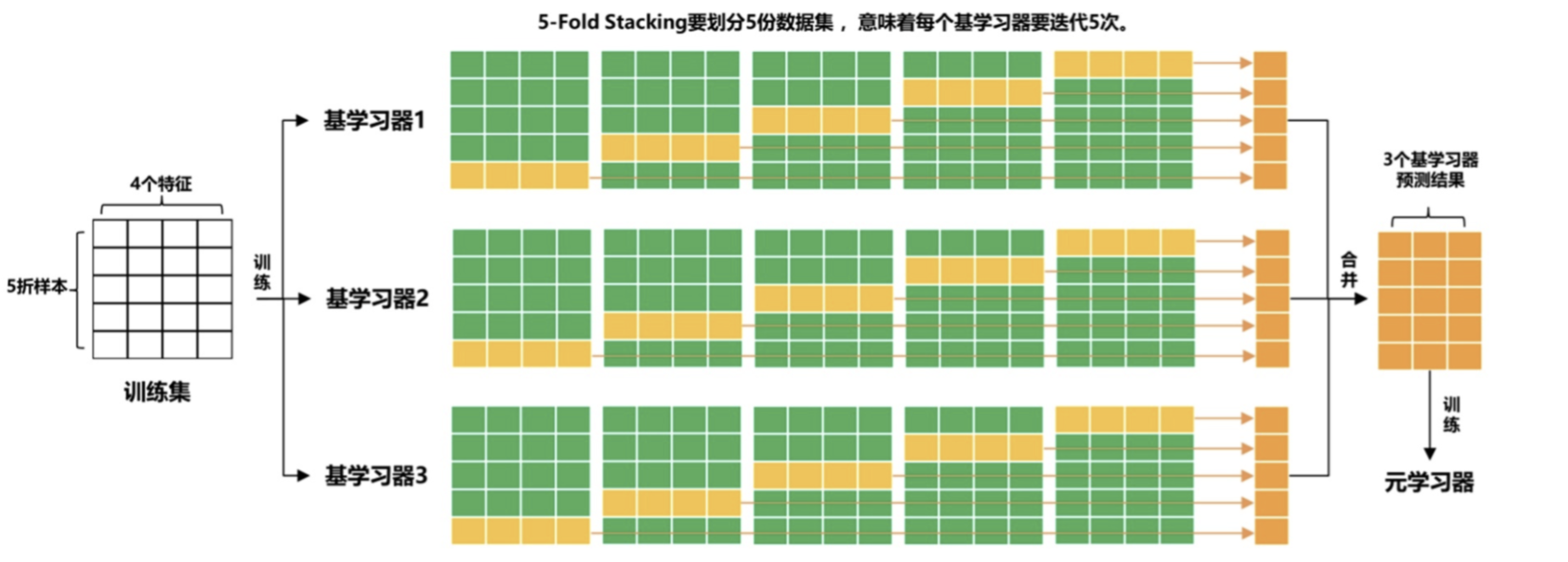
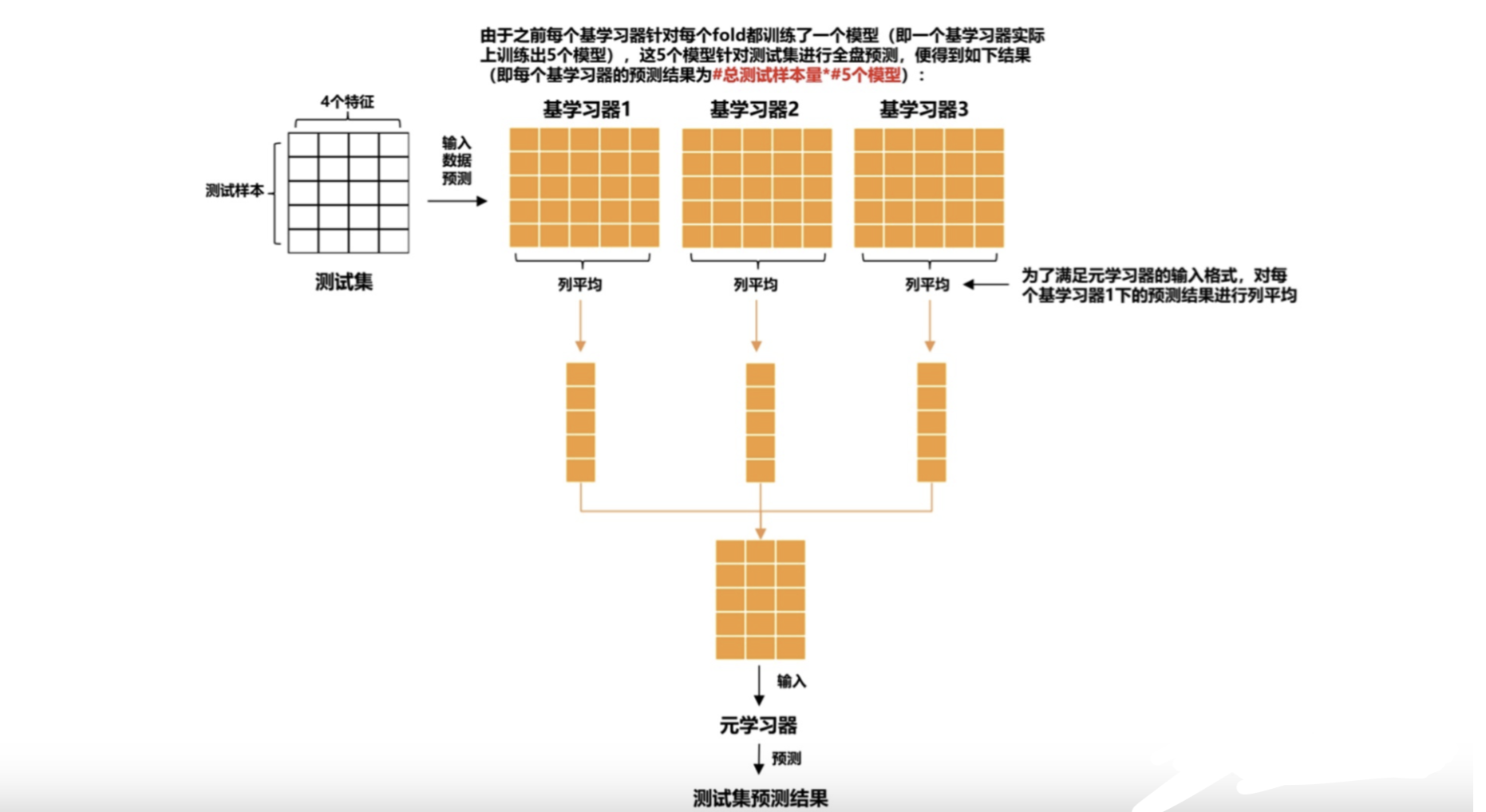
Blending算法
Blending(混合)是一种集成学习方法,它与 Stacking(堆叠)相似,但通常更简单、更直接。Blending 的主要目的是结合多个不同的预测模型,以提高整体预测的准确性。
基本概念
- 基学习器(Base Learners):这些是混合过程中使用的初级学习模型。它们可以是不同类型的算法,如随机森林、神经网络、支持向量机等。
- 混合器(Blender):这是一个简单的模型或算法,用于结合基学习器的预测结果。
工作流程
- 分割数据集:首先,将数据集分为两部分。第一部分用于训练基学习器,第二部分用于生成混合数据。
- 训练基学习器:在第一部分数据上训练各个基学习器。
- 创建混合数据集:使用基学习器在第二部分数据上做出预测,并将这些预测用作新的特征集,这个特征集将用于训练混合器。
- 训练混合器:混合器在这个新的特征集上进行训练,学习如何结合基学习器的预测。
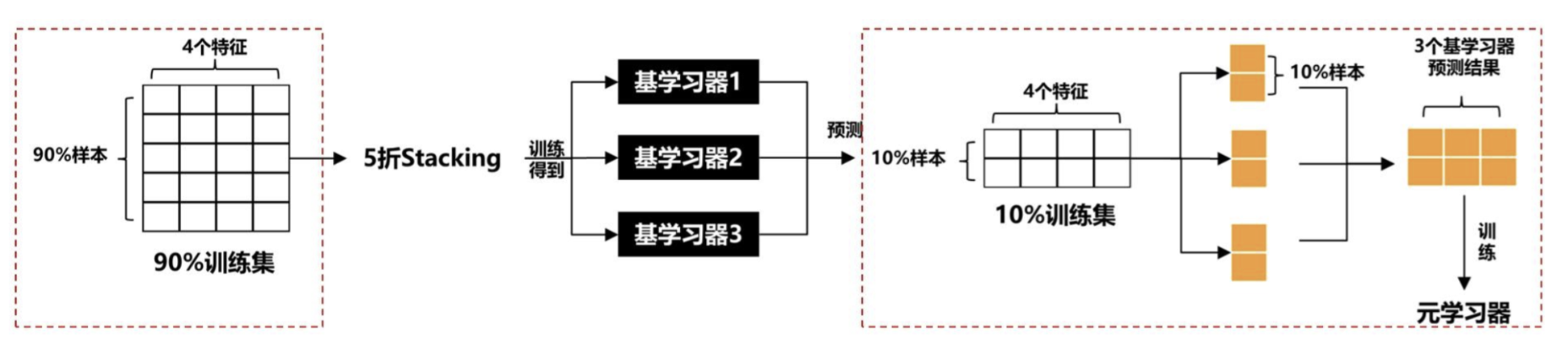
案例分享
下面我们使用 Stacking 算法和 Blending 算法来进行房屋价格预测。
Stacking 算法案例
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.svm import SVR
from mlxtend.regressor import StackingRegressor
# 加载加州住房数据集
housing = fetch_california_housing()
X, y = housing.data, housing.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义基学习器
svr = SVR(kernel='linear')
rf = RandomForestRegressor(n_estimators=10, random_state=42)
gb = GradientBoostingRegressor(random_state=42)
# 定义元学习器
stacked_regressor = StackingRegressor(regressors=[svr, rf], meta_regressor=gb)
# 训练模型
stacked_regressor.fit(X_train, y_train)
# 预测和评估
y_pred = stacked_regressor.predict(X_test)
print("Stacking Mean Squared Error:", mean_squared_error(y_test, y_pred))
#
Blending 算法案例
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
# 加载加州住房数据集
housing = fetch_california_housing()
X, y = housing.data, housing.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 进一步分割训练数据用于混合
X_train_base, X_train_meta, y_train_base, y_train_meta = train_test_split(X_train, y_train, test_size=0.5, random_state=42)
# 定义基学习器
svr = SVR(kernel='linear')
rf = RandomForestRegressor(n_estimators=10, random_state=42)
# 训练基学习器
svr.fit(X_train_base, y_train_base)
rf.fit(X_train_base, y_train_base)
# 生成混合数据集
svr_pred = svr.predict(X_train_meta)
rf_pred = rf.predict(X_train_meta)
blended_features = np.column_stack((svr_pred, rf_pred))
# 训练混合器
blender = LinearRegression()
blender.fit(blended_features, y_train_meta)
# 在测试数据上进行预测
test_pred_svr = svr.predict(X_test)
test_pred_rf = rf.predict(X_test)
test_blended_features = np.column_stack((test_pred_svr, test_pred_rf))
y_pred_blend = blender.predict(test_blended_features)
print("Blending Mean Squared Error:", mean_squared_error(y_test, y_pred_blend))
#
请列举 Stacking 方法的主要优点和缺点?
优点:
- 性能提升:通过组合多个基学习器,然后利用元学习器对它们的预测结果进行融合,从而提高模型的预测性能。
- 提高泛化能力:Stacking 能够充分利用多个基学习器的多样性,可以同时使用不同类型的模型,提高泛化能力。
- 模型多样性:可以结合不同类型的模型,如线性模型、树模型等,使得模型更全面地学习数据的特征。
- 鲁棒性:由于 Stacking 方法综合了多个基学习器的优势,使得模型具有较强的鲁棒性,不容易受到单个基学习器性能波动的影响。
2)缺点:
- 计算成本高:Stacking 涉及多个模型的训练,因此通常比单个模型计算复杂度高。
- 调参困难:由于涉及多个模型,Stacking 的超参数空间更大,调参过程可能更复杂和耗时。
- 过拟合风险:由于 Stacking 方法涉及多个模型的融合,如果基学习器或元学习器过于复杂,可能导致过拟合。
- 可解释性差:Stacking 方法结构较复杂,涉及多个模型的组合,使得模型的可解释性相对较差。
在构建 Stacking 模型时,一般会选择简单的元学习器(如线性回归 LR 或随机森林 RF),为什么?
在构建 Stacking 模型时,选择简单的元学习器是一种常见的做法,主要是因为。
-
避免过拟合:元学习器的主要任务是学习如何结合基学习器的预测。如果元学习器太复杂,它可能会学习到基学习器预测中的噪声,从而导致过拟合。
-
减少计算成本:使用一个简单的元学习器可以减少总体的计算成本。
-
可解释性:简单的元学习器(如线性回归)使得 Stacking 模型更易于理解和解释。
请比较 Blending 算法与 Stacking 算法的异同?
Blending 算法和 Stacking 算法都是集成学习方法,用于结合多个模型以提高预测的准确性。
相同点
- 集成多个模型:两者都通过结合多个基学习器(如决策树、神经网络等)的预测来提高性能。
- 改善预测准确性:目标是通过集成不同模型的优点,减少预测误差。
- 减少过拟合风险:多模型的集成可以减少单个模型过拟合的风险。
不同点
- 训练方法
- Stacking:通常涉及将基学习器的预测作为输入来训练元学习器。这个过程涉及多层学习,其中元学习器试图学习如何最好地结合基学习器的预测。
- Blending:通常更简单,涉及将基学习器的预测直接作为特征来训练一个最终的模型(混合器)。Blending 通常不要求像Stacking 那样的多层结构。
- 数据分割
- Stacking:通常使用交叉验证来训练基学习器,并生成用于元学习器训练的数据。
- Blending:通常将训练数据分为两部分,一部分用于训练基学习器,另一部分用于生成混合器的训练数据。
- 模型复杂性和计算成本
- Stacking:通常比Blending更复杂,需要更多的时间和计算资源。
- Blending:相对简单,计算成本通常较低。
Stacking 算法在训练基模型的时候为什么需要交叉验证?
在 Stacking 算法中,使用交叉验证(Cross-Validation, CV)来训练基学习器是非常关键的,主要是因为。
- 提高模型泛化能力:通过交叉验证,基学习器在不同的子集上进行训练和验证,这有助于提高模型对新数据的泛化能力。
- 优化模型性能:交叉验证允许对基学习器进行更细致的调整,比如参数设置和模型选择,从而优化每个基学习器的性能。
- 提高稳定性:交叉验证通过在多个数据分割上评估模型,减少了模型性能的方差,提高了模型的稳定性和可靠性。
在实际应用中,如何防止Stacking算法过拟合?
在实际应用中,防止 Stacking 算法过拟合是一个重要的考虑因素。以下是一些防止 Stacking 过拟合的策略。
- 使用交叉验证(CV):在训练基学习器时使用交叉验证可以帮助防止信息泄露和过拟合。
- 选择合适的基学习器和元学习器:选择较为简单的模型作为基学习器或元学习器,可以减少模型复杂度,从而降低过拟合风险。
- 模型正则化:对基学习器和元学习器应用适当的正则化(如L1或L2正则化)可以防止模型变得过于复杂,从而降低过拟合的风险。
- 集成多样化模型:确保堆叠中的基学习器具有足够的多样性。
- 避免复杂的元学习器:复杂的元学习器(如深度神经网络)可能会学习到基学习器预测的噪声,导致过拟合。通常,简单的元学习器(如线性回归或轻量级的梯度提升树)就足够了。